Transfer Learning, Pre-Training, or Fine-Tuning?
Learn how machine learning concepts have evolved in GenAI times
Back in the early days of machine learning, when model training was a weekend project on a few GPUs, the concepts of pre-training, fine-tuning, and transfer learning felt simple and straightforward. You’d grab a pre-trained model, slap a classifier head on top, fine-tune it for your task, and call it a day.
If you’ve been around since the days when you could fine-tune a model like GPT-2 or BERT on a consumer GPU, today’s terminology might feel… confusing. Concepts that were once well-defined now describe workflows that are vastly different, due to the needs of large language model providers.
Machine learning hasn’t just evolved in scale; the way we communicate about it has adapted to these new workflows. Understanding how these concepts have evolved — and keeping communication clear — may be the key to bring a level of sanity to some technical discussions!
TL;DR
Neural Network Era (pre ChatGPT)
- Pre-Training: Training a large model on general data (foundation).
- Fine-Tuning: Adjusting the pre-trained model for a specific task.
- Transfer Learning: Using knowledge from one task/model for another.
GenAI Era (2024/25)
- Pre-Training: Done by providers (OpenAI, Anthropic) — model learns broadly.
- Fine-Tuning: You tailor a model for your app (e.g., OpenAI’s fine-tuning API).
- Transfer Learning: Happens by default in APIs — LLMs adapt their pre-trained knowledge for your queries/tasks.
Pre-Training: From Small-Scale to Industrial
In the earlier days, pre-training meant teaching a model foundational knowledge. For images, it might involve detecting edges and textures; for text, learning grammar and syntax. This process was ambitious but achievable with enough patience and a few GPUs. A lab — or even a well-resourced individual — could manage it.
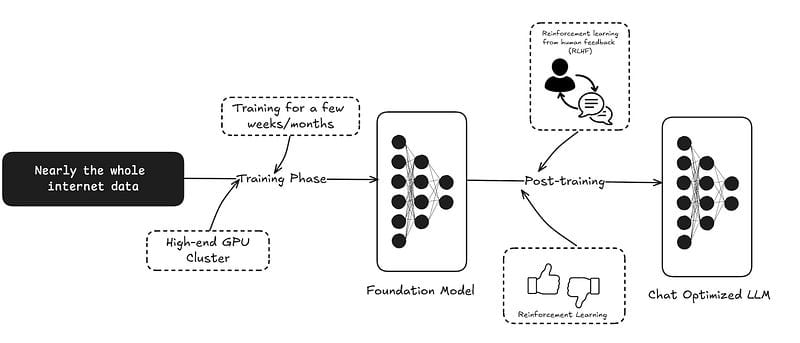
Today, in the GenAI Era, pre-training typically involves trillions of tokens, enormous datasets, and infrastructure spanning thousands of GPUs. Models like GPT-4 and Claude aren’t just pre-trained; they’re foundation models, capable of general-purpose reasoning across countless domains.
- Example: Training GPT-4 involved massive datasets sourced from diverse online content, enabling it to generalize across tasks like answering questions, summarizing, and coding.
This shift means pre-training has moved out of reach for most. It’s no longer a step in your workflow — it’s the foundation of the modern GenAI ecosystem, handled by a handful of organizations with the resources to scale.
Most chat models today go through a post-training step right after that which includes reinforcement learning with human feedback (RLHF). That process turns a Language Model — a purely next-token predictor — into a human friendly model with chat-like responses.
That's called instruct-tune, which is part of fine-tuning. But in most LLM contexts, talking about fine tuning means domain-specific tuning, which we'll cover below.
Fine-Tuning: A Subtle Evolution
In the Neural Network Era, fine-tuning was straightforward. You’d take a pre-trained model, attach a new layer (head) for your specific task, and train it on your dataset. The base model remained largely untouched while the task-specific head learned to classify, predict, or generate outputs.
In the GenAI Era, fine-tuning now means adjusting the model’s weights directly, often across all layers, without adding anything new. It’s about teaching the model to specialize for your use case — aligning its behavior to your goals — while preserving its general-purpose capabilities.
- Example: OpenAI’s fine-tuning API allows companies to tailor GPT-4 for tasks like generating technical documentation in a specific style or answering niche domain questions.
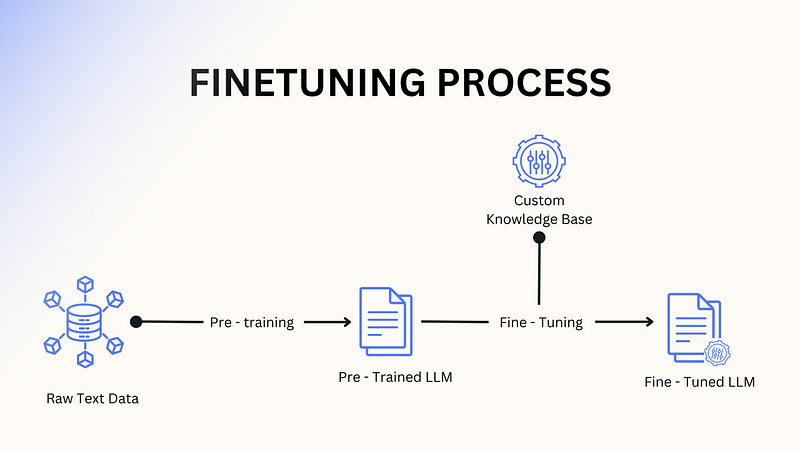
Fine-tuning has shifted from structural changes to subtle behavioral optimization, enabling businesses to adapt powerful models to their specific needs.
Transfer Learning: The Default Mode
In the Neural Network Era, transfer learning was the cornerstone of practical workflows. You’d freeze early layers of a model — where general features were stored — and fine-tune the task-specific parts. It was an efficient way to reuse knowledge without starting from scratch.
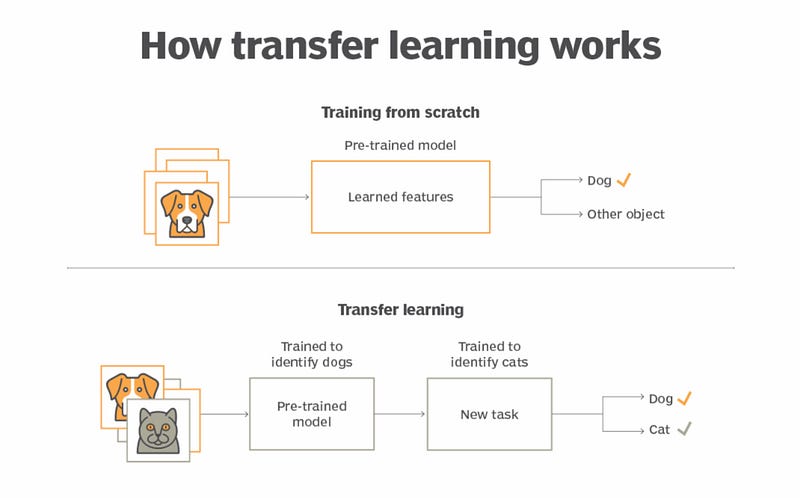
In the GenAI Era, transfer learning is baked into the system. These models are inherently general-purpose, and adapting them to a new task often requires nothing more than a well-crafted prompt. Fine-tuning may not even be necessary.
- Example: Instead of fine-tuning GPT-4 to draft legal contracts, you can guide it with a few example prompts, leveraging its pre-trained knowledge dynamically.
Transfer learning now feels invisible, happening seamlessly through interaction rather than explicit retraining.
The transition from Neural Networks to GenAI times has fundamentally changed the scale, workflows, and communication around these core concepts. Pre-training is now an industrial-scale operation, fine-tuning focuses on subtle adjustments rather than structural changes, and transfer learning is seamlessly integrated into modern GenAI workflows.
For those who started in the small-scale era, these shifts might seem like a radical departure. But the principles remain consistent. Understanding how these concepts have adapted in the GenAI paradigm helps bridge the gap between traditional workflows and the expansive potential of modern AI.
At Langflow, we’re building the fatest path to AI development — from prototyping to production. It’s open-source and features a free cloud service! Check it out at www.langflow.org ✨



