How to Create Secure AI Applications


You’ve built an impressive AI agent. It can query databases, call external APIs, and even process payments. But with every API call to a third-party LLM provider, you're potentially broadcasting sensitive data—API keys, PII, financial information—into a black box. Relying on the vendor's privacy policy is not a security strategy.
It’s time to move beyond the default and engineer security into your AI applications from the ground up. This isn't about a single solution, but a spectrum of choices. We call it the Ladder of AI Security.
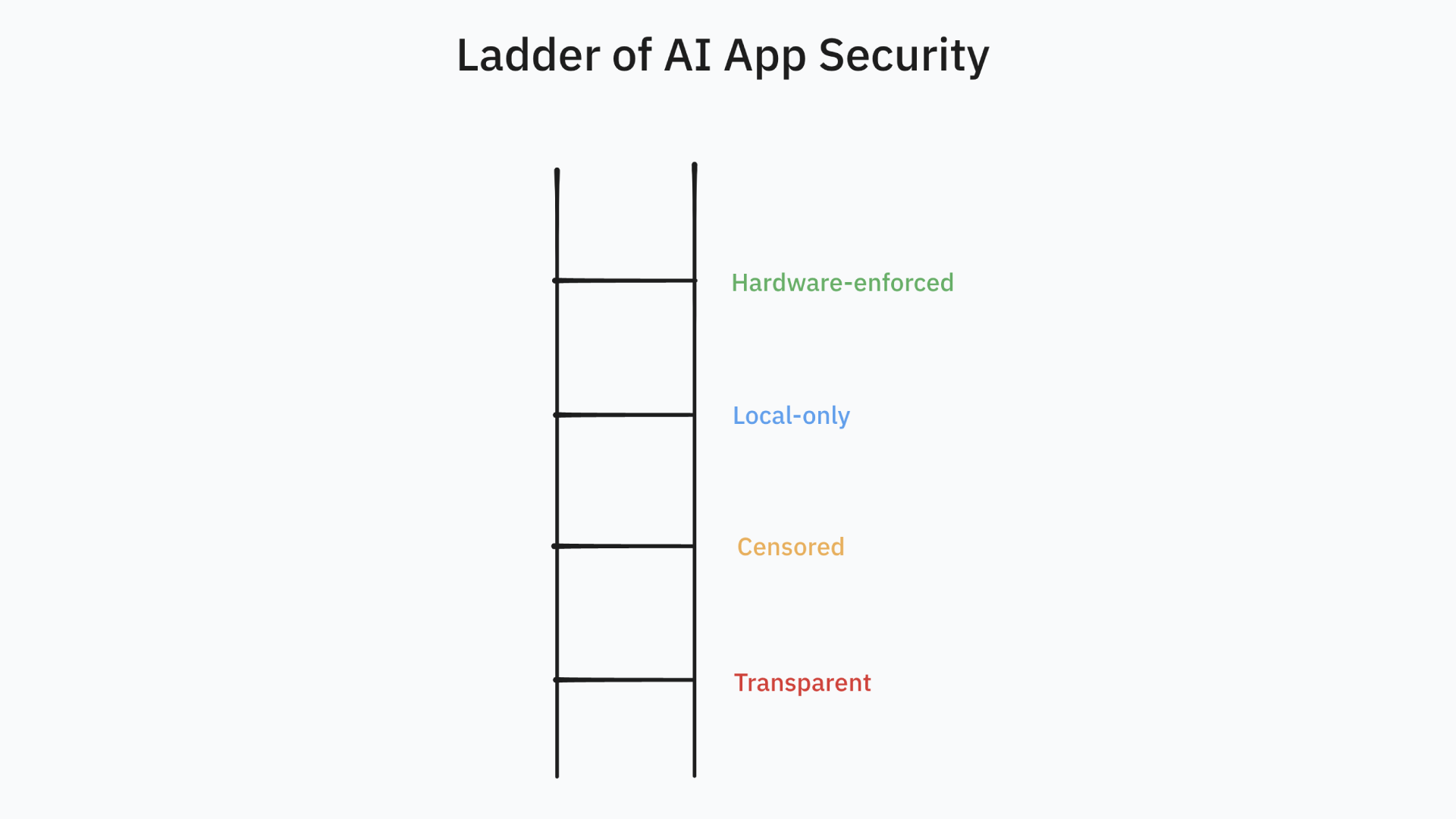
This guide will walk you through four distinct levels of security for AI agents, complete with code examples using the Vercel AI SDK and Node.js.
Level 1: Transparent Agents
This is where most projects start. You connect your agent directly to a provider like OpenAI, passing data back and forth in plaintext.
The architecture is what we're used to:
User -> Your App -> OpenAI API (Plaintext) -> Your App -> User
Risks
There are three main risks:
- Data Exposure to Vendor: Your prompts and tool outputs, which may contain sensitive data, are sent to a third party. You have no control over how they store, process, or use that data for training future models.
- Man-in-the-Middle: While TLS helps, any compromise on your server or the network path exposes data.
- Client-Side Vulnerabilities: If secrets are handled in the browser, a malicious extension can easily scrape them.
A simple Langflow or AI SDK implementation often starts here. It's fast to prototype but not production-ready for sensitive workflows.
// The default, insecure approach
const { text } = await generateText({
model: openai("gpt-4-turbo"),
prompt: `Buy product 456 using credit card ${process.env.USER_CREDIT_CARD}`,
});
This is a ticking time bomb. Let's defuse it.
Level 2: Strategic Censorship
The core principle here is simple: the LLM should never see the raw secret. Instead, we treat the LLM as an untrusted orchestration engine. We give it an encrypted "token" or "lockbox" that it can pass around but cannot open. Only our application code holds the key.
The Architecture
- Fetch Secret: Your application retrieves a sensitive token (e.g., credit card details) from a secure store.
- Encrypt: Before sending it to the LLM as part of a tool's output, you encrypt the token using a key the LLM never sees.
- Orchestrate: The LLM receives the encrypted ciphertext and the non-secret initialization vector (IV). It decides to use another tool, passing the ciphertext as an argument.
- Decrypt & Execute: Your application code receives the ciphertext from the LLM, decrypts it with its private key, and uses the raw secret to perform the required action.
Let's implement this using Node.js's built-in crypto module. Never roll your own crypto.
Step 1: Encryption & Decryption Utilities
We'll use AES-256-GCM, a modern, authenticated symmetric cipher.
// crypto-utils.js
// Use a secure key management system in production (e.g., AWS KMS, HashiCorp Vault)
// For this example, we'll generate one on the fly.
export const createKey = () =>
crypto.subtle.generateKey(
{ name: "AES-GCM", length: 256 },
true, // extractable
["encrypt", "decrypt"]
);
export async function encrypt(data, key) {
const iv = webcrypto.getRandomValues(new Uint8Array(12)); // GCM standard is 12 bytes
const encodedData = new TextEncoder().encode(JSON.stringify(data));
const ciphertext = await webcrypto.subtle.encrypt(
{ name: "AES-GCM", iv },
key,
encodedData
);
// Return IV and ciphertext, both needed for decryption.
// Base64 encode for easy transport in JSON.
return {
iv: Buffer.from(iv).toString("base64"),
ciphertext: Buffer.from(ciphertext).toString("base64"),
};
}
export async function decrypt(encrypted, key) {
const iv = Buffer.from(encrypted.iv, "base64");
const ciphertext = Buffer.from(encrypted.ciphertext, "base64");
const decryptedData = await webcrypto.subtle.decrypt(
{ name: "AES-GCM", iv },
key,
ciphertext
);
return JSON.parse(new TextDecoder().decode(decryptedData));
}
Step 2: Integrating with an AI Agent
Now, let's wire this into our Vercel AI SDK agent.
import { generateText } from "ai";
import { openai } from "@ai-sdk/openai";
import { z } from "zod";
import { tool } from "ai";
import { createKey, encrypt, decrypt } from "./crypto-utils.js";
async function main() {
const key = await createKey();
const { text, toolResults } = await generateText({
model: openai("gpt-4o"),
maxToolRoundtrips: 5,
tools: {
// Tool to get the card. It returns an *encrypted* object.
getCreditCard: tool({
description: "Get the credit card for a user ID.",
parameters: z.object({ userId: z.string() }),
execute: async ({ userId }) => {
console.log(`[APP] Getting card for user: ${userId}`);
const cardData = {
number: "1234-5678-9012-3456",
exp: "12/26",
name: "Blessing K.",
}; // Fetched from DB/Vault
const encryptedCard = await encrypt(cardData, key);
console.log("[APP] Encrypting card data. Giving LLM the ciphertext.");
// The LLM only sees the encrypted data
return encryptedCard;
},
}),
// Tool to buy a product. It *expects* an encrypted object.
buyProduct: tool({
description:
"Buy a product with the provided encrypted credit card object.",
parameters: z.object({
productId: z.string(),
encryptedCard: z.object({
iv: z.string(),
ciphertext: z.string(),
}),
}),
execute: async ({ productId, encryptedCard }) => {
console.log("[APP] Received encrypted card from LLM. Decrypting...");
const cardData = await decrypt(encryptedCard, key);
console.log(
`[SECURE EXECUTION] Buying product ${productId} with card ending in ${cardData.number.slice(
-4
)}`
);
return { success: true, productId };
},
}),
},
prompt:
"Get the credit card for user 123 and then buy product 456 with it.",
});
console.log(`\nFinal Result: ${text}`);
}
main();
This pattern is incredibly powerful. The LLM acts as a stateless function orchestrator, passing opaque handles (our encrypted JSON) between tools, while our application maintains the security boundary.
Level 3: Local-Only
Even with encryption, you're still sending metadata and non-sensitive prompt text to a third party. For maximum privacy, you can eliminate the third party entirely by running the model locally.
Tools like Ollama have made this remarkably accessible.
The architecture looks something like this:
User -> Your App -> Local LLM (Ollama) -> Your App -> User
The Benefit
- Total Data Sovereignty: No data ever leaves your machine or your VPC (Virtual Private Cloud). You don't need to encrypt data for the LLM, because you control the LLM's environment.
- No Vendor Lock-in: Swap out open-weight models as you see fit.
- Cost: No per-token API fees (though there are hardware costs).
The Catch
- Hardware: You need a machine with sufficient RAM and, for good performance, a powerful GPU.
- New Security Boundary: The risk now shifts from a third-party vendor to the security of your own host machine. If an attacker gains access to the machine, they can read the process memory and potentially access the secrets.
Langflow's Agent component natively supports Ollama. All you've got to do is drag an Ollama component into your flow, enter the connection details, choose a model, and then wire it up to the Agent, choosing "Custom" for the Agent's LLM choice.
If you're using the Vercel AI SDK, here's how to point it to a local Ollama instance:
import { ollama } from "ollama-ai-provider";
const { text } = await generateText({
// Point to your local Ollama instance running a model like phi3
model: ollama("phi3"),
prompt: "What is the capital of France?",
});
It's that simple. All network traffic now stays on localhost.
Level 4: Hardware-Enforced Security
This is the gold standard for secure computing. It solves the problem of a compromised host by leveraging special hardware features.
A Trusted Execution Environment (TEE) is an isolated area within a CPU. Code and data loaded inside a TEE are protected at the hardware level, meaning even the host operating system, kernel, or a cloud provider's hypervisor or administrators cannot access its memory.
With this architecture, your entire AI agent, or at least the part that handles secrets, runs inside this hardware-secured enclave.
Some examples of TEEs in the wild are:
- Apple's "Private Cloud Compute" for Apple Intelligence and on-device "Secure Enclave" that stores keys for Apple Pay, iCloud Keychain, and even your fingerprints and face ID.
- AWS' Nitro Enclaves
- Azure Confidential Computing
- Google Cloud Confidential Computing
How it works
- Attestation: The TEE cryptographically proves to the client that it is a genuine TEE running the expected code.
- Sealed Data: The TEE can encrypt data using a key that is fused into the hardware and inaccessible to the outside world.
- Secure Inference: An LLM (usually a smaller, highly quantized model) can run inference entirely within the TEE. Any sensitive data it processes is protected in memory.
When to use this
This is for high-stakes applications: processing medical records, financial data, or national security information. Implementing a TEE-based solution is complex and outside the scope of a simple blog post, but it's crucial to know this layer of security exists for when the stakes are highest.
Choosing Your Level
| Level | Core Principle | Mitigates Risk Of... | When to Use |
|---|---|---|---|
| 1. Transparent | Speed & Simplicity | - | Prototyping, non-sensitive data. |
| 2. Censorship | LLM as Untrusted Orchestrator | Vendor data misuse, sending raw secrets over the wire. | Most production apps with sensitive tokens (API keys, PII). |
| 3. Local-Only | Full Data Sovereignty | All third-party data exposure. | Privacy-first apps, internal enterprise tools, air-gapped environments. |
| 4. Hardware | Trust No One (Not Even the Host) | Compromised host machine, malicious cloud admin. | High-security industries (finance, healthcare), government. |
Security is a conscious design choice. By understanding this ladder, you can move from a default state of high risk to an intentional, secure architecture that protects your users and your business.
What level is your project at? Share your own security strategies and challenges with us on X or Discord.
Frequently Asked Questions (FAQ)
Doesn't encrypting and decrypting data on every tool call add a lot of performance overhead?
Yes, but it's almost always negligible. Modern CPUs have hardware acceleration for AES, meaning encryption/decryption operations take microseconds. In contrast, a network roundtrip and inference from a large language model take hundreds or thousands of milliseconds. The security gain from a sub-millisecond operation is an excellent trade-off. Your bottleneck will be the LLM, not the crypto.
You glossed over key management. What's a realistic way to handle the encryption key in production?
Excellent question. The createKey() function in the example is for demonstration only. In a real-world application, you must never store keys in code. Use a dedicated secret management service:
- Cloud KMS (Best Practice): Use AWS KMS, Google Cloud KMS, or Azure Key Vault. Your application is granted IAM permissions to use a key for encryption/decryption, but it never actually holds the key material itself. This is the most secure and common pattern.
- Vaults: Use a tool like HashiCorp Vault, which provides centralized secrets management, dynamic secrets, and tight access control.
- Environment Variables: A step up from hardcoding, but still risky as variables can be exposed in logs, deployment configurations, or shell history. Use this only in secure, tightly controlled environments.
Are local, open-weight models from Ollama really good enough for complex tool use?
It depends on the model size and the task complexity.
- High-End Models: Larger models (e.g., Llama 3 70B, Mixtral 8x7B) have excellent function-calling and tool-use capabilities, often rivaling proprietary models.
- Smaller Models: Smaller models (e.g., 7B or 8B parameter models) may struggle with multi-step reasoning or consistently generating perfectly formatted JSON for tool calls. You may need more robust prompt engineering, output parsing, and error handling. It's a trade-off between performance, hardware cost, and capability. Always test your specific use case.
Can I combine these security levels? For instance, using encryption with a local LLM?
Absolutely, and it's a great example of defense-in-depth. While a local LLM (Level 3) prevents data from leaving your server, the data still exists in plaintext in the model's memory context. If you also implement encryption (Level 2), you protect that data from other processes on the same machine or a potential memory dump by an attacker. This ensures the raw secret only exists for the brief moment it's being used by your tool's execute function and is never in the LLM's context, even locally.
This is great for data protection, but what about prompt injection?
This is a critical distinction. The techniques in this article primarily address data confidentiality and privacy—preventing the LLM and third parties from seeing sensitive data. Prompt injection is an attack on the integrity and control of the LLM, where an attacker uses malicious input to trick the agent into performing unintended actions. They are separate but related problems. To combat prompt injection, you need other strategies like:
- Strong input sanitization.
- Using separate, well-defined system and user prompts.
- Implementing fine-grained permissions for tools.
- Adding a human-in-the-loop confirmation step for destructive actions (like finalizing a purchase).
The article focuses on coding with the Vercel AI SDK. How does a visual tool like Langflow fit into building these secure AI agents?
Langflow is the ideal visual front-end for designing and prototyping the exact AI agents discussed in this article. While the code examples show the underlying logic, Langflow allows you to build the same agent architecture—with models, tools, and prompts—using a drag-and-drop interface. This makes it incredibly fast to iterate and is perfect for developers who want to visualize their agent's flow or for teams with members who are less focused on coding. You can build in Langflow first, then export to code to add complex security logic.
How can I connect an AI agent built in Langflow to a local model with Ollama, as mentioned in Level 3?
Langflow has excellent, first-class support for Ollama, making it one of the easiest ways to build and run AI applications with local LLMs. In the Langflow interface, you simply add an Ollama component, point it to your local Ollama server URL (e.g., http://localhost:11434), and select the model you have running (like Mistral or Llama 3). This allows your Langflow agent to achieve Level 3 security (Local-Only) without writing any custom integration code.
Can I implement the Level 2 "Censorship" (encryption/decryption) pattern directly within my Langflow AI application?
Yes. This is an advanced use case where Langflow's flexibility shines. You would use Langflow's "Custom Component" feature to create nodes that contain your Python security code. One component would contain the encrypt function, and another would contain the decrypt function from the blog post. Your agent's flow would then route the data through these custom components at the appropriate steps, creating a secure, encrypted workflow within the visual environment of Langflow.
What is the main advantage of using Langflow for AI agent development over coding everything from scratch?
The primary advantage of Langflow is speed and clarity. Langflow abstracts away the boilerplate code, allowing you to focus on the agent's logic, a concept central to modern AI. You can visually see how the prompt, tools, and LLM connect, making it easier to debug and explain to others. For building AI applications, Langflow acts as a powerful orchestrator that helps you experiment with different models (like swapping OpenAI for a local Ollama model) with just a few clicks.
So, for someone building a new AI application, is Langflow the recommended starting point?
For a vast number of AI applications, yes. Langflow is the perfect starting point for designing your agent's core logic. It allows you to quickly validate your ideas, test different prompts, and ensure your tool chain works as expected. Because Langflow is built on open-source libraries like LangChain, the concepts are fully transferable, making it an essential tool for both learning and professional AI agent development.